یافتن سوزن در انبار کاه: چگونه دادههای بدون ساختار را مدیریت کنیم
دنیای دیجیتال امروزی حجم بسیار بالایی از داده تولید میکند. با رشد سریع رسانههای مبتنی بر اینترنت و کسبوکارهایی که به سمت عملکرد آنلاین پیش میروند جای تعجب ندارد که آمریکا به تنهایی در هر دقیقه بیش از ۲.۵ میلیون گیگابایت داده تولید میکند. تمام این اطلاعات باید در جایی ذخیره شوند. بیشتر اینها حدود ۱۴۵۰ اگزابایت ظرفیت مراکز دادهی جهان را اشغال کردهاند. سازمانهایی که توانایی مدیریت موثر دادههایشان را دارند میتوانند بینشهای ارزشمندی کسب کنند و برنامههای تجاریشان را بر این اساس تطبیق دهند.
مدیریت ضعیف دادهها موجب هزینههای قابل توجهی نه تنها برای ذخیرهی اطلاعات بلکه به دلیل از دست دادن فرصتها میشود. برخورداری از بهترین اطلاعات دنیا با داشتن اطلاعات زیادی که نمیتوان از آنها استفاده کرد، برابر نیست. این شبیه یک پیشنهاد ساده به نظر میرسد ولی متاسفانه اطلاعات چیزی نیست که شکلدهی و مدیریت آن به این سادگی باشد. یکی از بزرگترین چالشهایی که سازمانها در سودمندسازی اطلاعاتشان با آن روبهرو هستند، مواجهه با دادههای بدون ساختار است.
دادهی بدون ساختار چیست؟
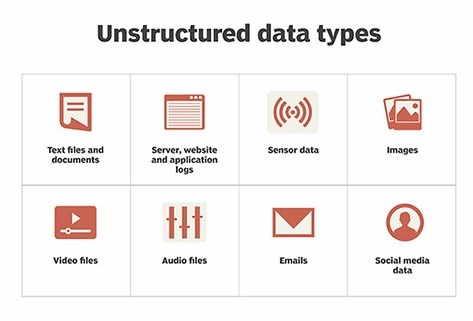
درک تفاوت بین دادهی «بدون ساختار» و دادهی «ساختار یافته» به درک اینکه چگونه شکلهای اولیهی داده در اواسط قرن بیستم به فرم دیجیتال تبدیل شدند، کمک میکند. سوابق حسابداری و موجودیها به عمدهی دادههای اولیهی کامپیوتر شکل میدادند. از آنجا که این اطلاعات از قبل در ساختارهایی مشخص دستهبندی شده بودند، فرم دیجیتال آنها نیز سطحی از یکنواختی را حفظ کرده بود. فیلدهای داده در طولهایی از پیش تعریف شده و ویژگیهای فیلد مانند متن در مقابل رقم، با فیلدهای خاصی که در مکانهای ثابت در هر رکورد ظاهر میشوند، تنظیم شده بودند. این شکلهای دقیق طبقهبندی شده، امکان خواندن، جستجو و درک دادههای ساختار یافته را به آسانی مهیا میکرد. ولی دادهی بدون ساختار فرمت خاصی ندارد. این دادهها میتوانند در هر اندازه، قالب یا فرمی باشند که مدیریت و تجزیه و تحلیلشان را به طرز باورنکردنی سخت میکند.
محدودیت دادههای ساختار یافته به گونهای است که تنها شامل نوع و مقدار خاصی از اطلاعات در زمینههای تعریف شدهی مربوط به آن میشود ولی دادههای بدون ساختار چنین محدودیتی ندارند. دادههای ساختار یافته از الگوریتمهای پایهای استفاده میکنند که به راحتی قابلیت جستجو دارند ولی دادههای بدون ساختار از هیچ الگوی قابل پیشبینی که قابلیت پردازش توسط یک الگوریتم ساده را داشته باشد، استفاده نمیکنند.
دادههای بدون ساختار میتوانند از هر جایی نشأت بگیرند ولی بیشتر آنها به صورت مدرک، تصویر، ایمیل، ویدیو، فایل صوتی، صفحات وب یا خبرنامههای شبکههای اجتماعی وجود دارند. همچنین به این دلیل که سازمانهای بیشتری استراتژیهای عصر کامپیوتر را اتخاذ کردهاند، دستگاههای اینترنت اشیا در حال تبدیل شدن به منبع اصلی دادههای بدون ساختار هستند.
مدیریت دادههای بدون ساختار
محققات تخمین زدهاند که حدود ٪۸۰ دادههای تولید شده، بدون ساختارند. با وجود اینکه این دادهها حاوی اطلاعاتی هستند که میتوانند ارزشی باورنکردنی به سازمانها اعطا کنند، ولی بررسی و گزینش از میان آنها فوقالعاده سخت است. بیرون کشیدن بینشهای مدفون در مدارک، ایمیلها یا انواع مختلف فایلهای رسانهای برای یک الگوریتم ساده که جهت جستجوی نمونههای فیلد طراحی شده، کار بسیار پیچیدهای است. متاسفانه دادههای بدون ساختار در چنین مقیاس قابل توجهی وجود دارند که تجزیه و تحلیل آنها فراتر از ظرفیت انسانی هر سازمانی است.
فناوری شناختی و مبتنی بر هوش مصنوعی یکی از موثرترین ابزارها برای استخراج اطلاعات ارزشمند از دادههای بدون ساختار است. این برنامهها از قابلیت تفسیر، ارزیابی، برقراری ارتباط و نتیجهگیری از این دادهها برخوردارند که مدیریت و استفاده از آنها را آسانتر میکند. بدون این نوع تجزیه و تحلیل، حتی دانستن اینکه احتمالاً چه اطلاعات ارزشمندی در دادههای بدون ساختار نهفته است، سخت میباشد. در برخی موارد، این دادهها میتوانند مطرح کنندهی یک خطر امنیتی قابل توجه باشند.
شرکت عظیم نرمافزار ارتباط با مشتری Salesforce به روش بیرحمانهای متوجه این خطر امنیتی شد؛ زمانی که در سال ۲۰۱۶ ایمیل هک شدهی یکی از اعضای هیئت مدیره، اهداف دستیابی به لیست پیوست و استراتژیهای بازار را صورت عمومی منتشر کرد.
متاسفانه تجزیه و تحلیل دادههای بدون ساختار فوقالعاده پرتنش است. این کار به میزان قابل توجهی از منابع محاسباتی نیاز دارد که فراتر از توان زیرساختی اکثر شرکتهاست. حتی مدیریت ذخیرهسازی و دسترسی برای دادههای بدون ساختار در وهلهی اول یک مانع اصلی به حساب میآید. به این دلیل که روزانه دادههای بدون ساختار بیشتری ایجاد میشوند، نیازهای ذخیرهسازی و محاسبه به سرعت تغییر میکنند. راهحلهای امروزی زیرساخت IT احتمالاً توانایی سازگاری با نیازهای آتی یک شرکت را ندارند، بخصوص اگر این نیازها به سرعت در حال رشد باشند.
چگونه یک مرکز داده میتواند کمککننده باشد
مراکز دادهی امروزی به شرکتهایی که به دنبال روشهای بهتری برای مدیریت دادههای بدون ساختارشان هستند، راهحالهای قابل قیاس مختلفی پیشنهاد میکنند. مراکز داده با استفاده از زیرساخت مبتنی بر فضای ابری میتوانند سیاستهای دقیقی را به منظور کنترل نحوهی دریافت، جابهجایی، ذخیره، دستیابی و تجزیه و تحلیل دادهها تنظیم کنند. توانایی بالا بردن قدرت محاسباتی و فضای ذخیرهسازی، این را برای شرکتها ممکن میسازد تا از دادههایی که جمعآوری کردهاند بیشترین بهره را ببرند.
برای شرکتهایی که به دنبال گسترش رایانش مرزی هستند، یافتن یک مرکز داده که توانایی مدیریت نیازهای اطلاعاتی دستگاههای اینترنت اشیا را دارد، حیاتی است. اکثر ساختارهای رایانش مرزی دادهها را در مکانهای مختلفی که بر اساس مجموعهی دقیقی از پروتکلهاست، ذخیره میکنند. برخی از دادهها در مرز خود دستگاهها یا در مرز مراکز داده باقی میمانند، ولی برخی از آنها برای تجزیه و تحلیل به یک سرور مرکزی بازگردانده میشوند. شبکه برای اینکه بداند این دادههای بدون ساختار را به کجا ارسال کند، باید از مورد جستجو و آنچه در اولویت است، آگاه باشد.
همزمان که سازمانها اطلاعات گردآوری شده و توانایی ذخیرهسازیشان را گسترش میدهند، دادههای بدون ساختار چالشهای عظیمی را در برابر آنها قرار میدهند. اگر آنها راهحلی پایدار برای مدیریت و تجزیه و تحلیل این دادهها که بتواند بینشهای ارزشمندی را استخراج کند، نیابند، برای موفق شدن در محیطی رقابتی که از سرعت بالای پیشرفت برخوردار است، تقلا خواهند کرد. خوشبختانه یک مرکز دادهی قابل اعتماد میتواند برای شرکتها نیروی ذخیرهسازی و محاسباتی که برای ساخت آیندهشان نیاز دارند را تدارک ببیند.
1 thought on “یافتن سوزن در انبار کاه: چگونه دادههای بدون ساختار را مدیریت کنیم”